I have finally started toying with asp.net 2.0. I figured I better get with it before it was RTM. In any case I started with converting my homebrew website project.
The conversion utility was actually quite good, and made a number of changes; including folder structure, a few access modifiers, and most importantly removing the notion of "code behind" and replacing it with partial classes for pages and controls. It's not like it compiled right away, but nobody expected that. The first thing to note about 2.0 is that application code (specific business logic classes, special functional classes, interface definitions, etc) is now totally seperate from page and control code. In fact, that's one of the new asp.net system folders - "App_Code". The classes defined in this code are compiled to a seperate assembly at run time. The pages are compiled to their own assembly, and neither assembly is placed in the /bin directory any longer. You will find the assemblies in the temporary asp.net folder - as you would have in 1.1. For my homebrew application I see 3 assemblies - "App_Web_[random].dll"; "App_Code.[random].dll"; and "App_global.asax.[random].dll".
To take a look, I quickly open them in Relfector and verify the contents...
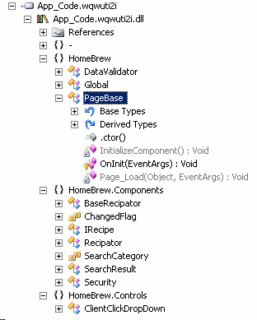 Yep, that's my app_code section of the site. Then I open the App_Web...
Yep, that's my app_code section of the site. Then I open the App_Web...
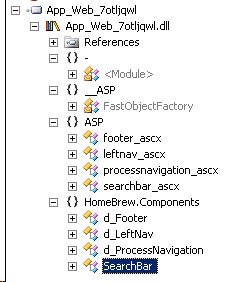 OK, not quite what I was expecting. Those are my controls (ascx), but I don't see my pages anywhere. Then I get what I expect from the global...
OK, not quite what I was expecting. Those are my controls (ascx), but I don't see my pages anywhere. Then I get what I expect from the global...
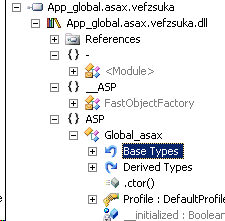
As you can see, this presents a new way of thinking about things like state managers, or custom configuration file readers. If you have this in application code, that code can no longer access instances of pages, nor can you late bind to these assemblies as they are not published by name to /bin.
I also use UIP on the site, which requires late binding, so that was one thing that was broken. The other was that I use a PageBase object for each page to create a master template style arrangement for common navigation, and footer - object instances of controls. The idea of a master template is built into asp.net 2.0, so I'll have to look at changing. In any event, the pages are also handled by a state manager. This is a business object which interacts with instances of pages and controls. Both of these concepts are broken in asp.net 2.0 because business logic classes (app_code) have no way of knowing about page classes. This problem is easily handled through a bit of indirection and late control binding as discussed here:
http://msdn.microsoft.com/asp.net/default.aspx?pull=/library/en-us/dnaspp/html/upgradingaspnet.asp
(look at the section on conversion issues)
This doesn't really put my code in a great place for 2.0, but does bring it to a point where it will compile. Because of the late binding, I actually end up having to move all of my app_code out to a separate assembly so I can reference it. I asked Scott Guthrie about this, and ended up having an interesting discussion (mostly with Simon Calvert actually) regarding the usefulness of the app_code section.
Simon gave the following reasons for the app_code architecture:
"App_code gives several benefits in developing applications:
it’s a known folder into which you can easily drop code files and not have to undergo any manual build step. This improves productivity in certain situations. App_code also has given semantics for arbitrary file extensions, not just regular code files. You can drop XSD or WSDL files and again, everything is done for you in the runtime. That is proxies are suto generated etc. Then in the designer tool, you get benefits in creating a class file and objects within the folder and have immediate intellisense and statement completion against your custom objects. This latter point is important in terms of productivity. If the app_code were a separate class library, then you would need to have separate projects, with references and undergo a build process in order to pull the updated class library to the web project.
App_code also allows sub-separation for specific scenarios like code languages, so you can easily separate out and manage the vb/c# in a shared code project for example
When using the app_code folder, the compilation process means that the assembly is compiled and that your pages all get references to that assembly automatically. It therefore is a separate assembly
Consuming types from the app_code folder is as simple as new-ing the type in your page codebehind for example and in cases where you might need the assembly name, we have strived to remove the requirement for the assembly name. For example, if you create a custom control in app_code then you can register it without referring to the assembly name. In cases where the name is required, you can use the moniker, “app_code”"
Well, I don't know enough yet about working in asp.net 2.0, so I am sure we'll find Simon's advice helpful as we move along. For my project, I still need that late binding so I have a separate assembly. They did mention potentially getting at the app_code via the BuildManager.GetType() method, but didn't expand on that, and I haven't looked into it.
My final issue to get the project actually working was to get SQL Server reconnected, and minor modification to an XmlValidatingReader (deprecated in 2.0) in the UIP to become an XmlReader with the proper attributes.




